In an ecosystem where conjectures and theories dominate debates, Google’s announcement on March 21 that rel next/prev tags are no longer used by the search engine provoked a virtual tidal wave.
We witnessed a landslide of tweets, an avalanche of questions, and a torrent of pointed comments on the most famous search engine.
If SEO was a stock market, this would have been another historic crash.
The Rel=Next/Prev Tag Backstory
In 2011, these famous tags were introduced in order to facilitate search engines’ treatment of duplicate content created by pagination.
This set of tags constituted a strong indexing signal because they enhanced search engine algorithms’ understanding with regard to duplicates.
Following Google’s recommendations, it became a standard best practice in SEO to indicate the next and previous pages of a paginated series in the page <head> using these tags.
Today, Google tells us that these tags are no longer taken into account because the algorithms have been sufficiently trained to be able to automatically detect the reason for certain cases of duplicates.
In machine learning terms, we have to admit that this is an interesting development. And that is exactly, in my opinion, where there is no room for debate.
The subject is not, in fact, to call into question other tags or to guess which schemas to use now so that Google will understand pagination.
Ilya Grigorik, Web Performance Engineer at Google, underscores this point:
no, use pagination. let me reframe it.. Googlebot is smart enough to find your next page by looking at the links on the page, we don’t need an explicit “prev, next” signal. and yes, there are other great reasons (e.g. a11y) for why you may want or need to add those still.
— Ilya Grigorik (@igrigorik) March 22, 2019
The False Problem of Pagination
By and large, when we read the reactions of the SEO community, we see that the vast majority of SEO professionals are worried that all of their articles/products will not be discovered.
In my opinion, that begs a different question and shines a light on an interesting element of how websites are designed today.
Although development techniques have changed (including some, like JavaScript, that leads to confusion and debate), navigational thinking has remained the same. This is true whether we’re talking about online publishing or ecommerce.
This is what I passionately denounced when working as an SEO in a web agency: why are ecommerce managers still trying to create as many product pages as there are available attributes/variants of a single product?
This was, and still is, pointless from my point of view.
Indexing signals continue to play a role, though pagination is no longer explicitly indicated. We could argue that something similar is occurring with rel=canonical.
More and more SEO pros report that Google ignores their declared canonical pages, particularly when the content does not correspond, and chooses its own.
Google does not appear to rely on indexing signals to discover product pages.
Other means of organizing a website also have significantly more importance than pagination, both for SEO and for users on your website, such as:
Pagination is just one means of organizing content. Rather than cogitating on the removal of an indexing signal, the real issue is to reflect on the need for pagination.
We often compare organic ranking to supermarket aisles. Each content has its place, as long as we reconsider the logic behind website development.
What the Data Tell Us
I’m going to take advantage of one of the best benefits in working for a crawler and log analyzer to share some data that we have access to, and at the same time try to explain the benefits of log analysis a little more clearly.
Analyzing log data allows us to see the URLs that receive Googlebot hits, and to count the hits to compute the frequency.
This portrait of Google’s behavior can reveal a number of insights into how the search engine approaches different type of pages in general and the site you are analyzing in particular.
In this case, I’m going to look at Google’s visits on all of the URLs over an extended period of time.
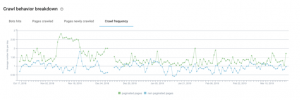
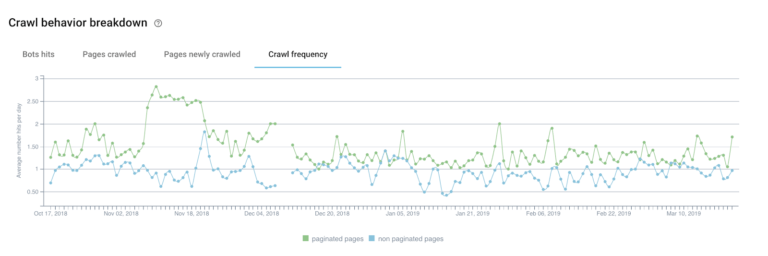
When we break down Google’s behavior on paginated and non-paginated pages, there is a noticeable difference between the crawl profile for the two series.
We can see that the crawl frequency is higher for pagination. This leads us to believe that Google needs more learning to detect and understand this type of series.
Even more interesting is taking a look at the crawl schema: what is the first URL crawled, and which URLs are crawled next?
For a single URL, we observe that Google follows pagination even though, in this case, it’s not in the right order.
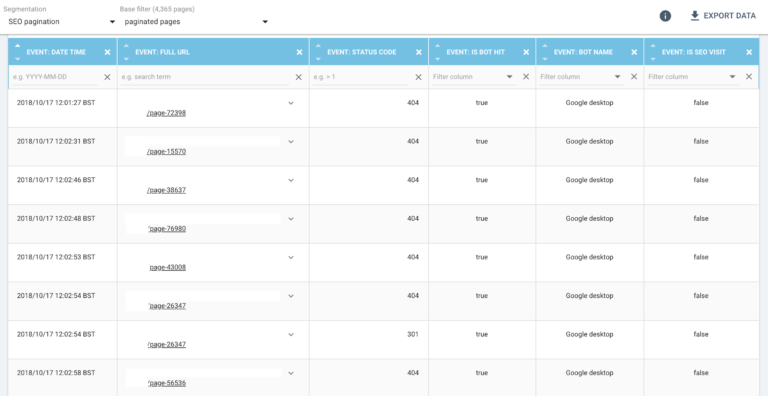
This type of information suggests that Google has identified paginated pages as a set that is different from typical content pages, but is still exploring the full set in order to determine what kind of pages it has discovered.
We should also remember that Google is not a human user.
Not only does Google use a scheduler to determine when to visit known URLs, but it might also be able to reach the right conclusions about a set of pages regardless of the order in which it visits them.
What Conclusions Can Be Drawn from Google’s Behavior?
Obviously, we would need to repeat this analysis on a larger dataset in order to draw generalizable conclusions.
However, a realistic conclusion based on this sample is that we note that the crawl schema occurs at a particular point in time: the series of paginated pages is crawled one page after another.
It seems Google needs this series of links, even if in this case it’s a short one in this particular case, in order to understand that it’s dealing with a paginated series.
Pending further study, if you’re wondering about rel pre/next and how to identify your pagination, here’s my suggestion:
- Make sure your pages are linked as a series.
- Think about how users navigate your site.
Google’s announcements and crawl data from logs indicate that the search engine has stopped using rel next/prev as an indexing factor not to annoy SEO professionals, but rather because it has now mastered pagination based on current site navigational logic.
More Resources:
Image Credits
Screenshots taken by author, April 2019